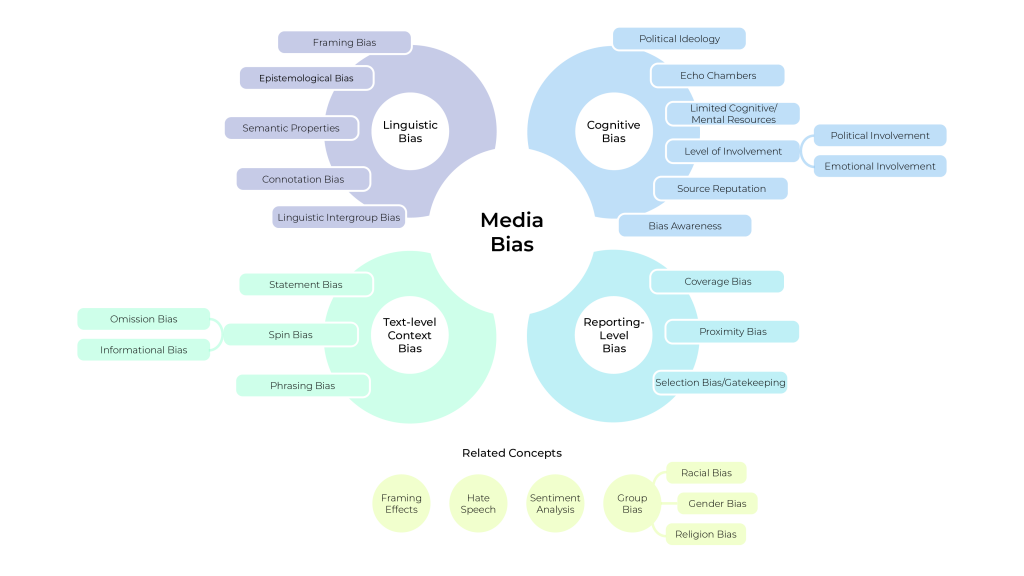
The media bias domain is fragmented. Across communication science, journalism, political studies, and NLP, “media bias” is defined in dramatically different ways. There is currently no universally accepted taxonomy that clearly and systematically distinguishes between the various types of media bias — such as selection bias, framing, and tone — or explains how they interrelate. Without this, researchers and AI systems alike struggle to align on what bias even is, let alone how to detect or mitigate it.
We aim to take on this challenge directly, and are developing an interdisciplinary, computationally grounded taxonomy of media bias, to be published and internationally validated by 2027.
Here’s how the group is building it:
We use large language models (LLMs) like GPT, Claude, and Mistral to extract definitions of media bias from over 200,000 academic papers. These definitions span multiple fields and perspectives — everything from how journalists describe bias to how cognitive scientists study perception and heuristics. Through advanced prompt engineering techniques (including zero-shot and contextual prompting), LLMs will systematically retrieve and standardize how bias is described. By the time we have them, we will semantially reduce the definitions to find similarities, and to help label, interpret, and hierarchically structure any clusters. The goal: a logically organized, semantically meaningful taxonomy that accounts for how bias operates across disciplines and domains.
Then, we will host an international workshop in early 2026, bringing together leading figures in NLP, journalism, media studies, and psychology to critique and refine the proposed taxonomy. Researchers from institutions like LMU Munich, the University of Zurich, Mila Montreal, and the University of Würzburg have already confirmed participation. The workshop will aim to ensure the taxonomy is clear, complete, and credible across fields.